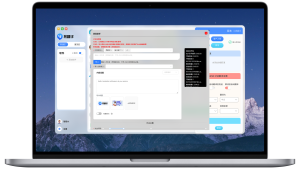
在易翻译里,打开“拍照取词/拍照翻译”功能,授予相机与存储权限,语言栏把源语言设为“吉尔吉斯语(Kyrgyz)”,目标语选中文或你要的语言;若列表里没有,先在“更多语言”或设置里下载吉尔吉斯离线包;拍照或导入图片,框选要识别的区域,等待OCR识别并查看翻译,需要时切换在线识别或手动校正、保存结果。

先说清楚:这是怎么回事(费曼式的快速理解)
简单来说,拍照识别就是把图片里的文字“看”成一串可读的字符(这一步叫OCR),然后把这些字符交给翻译引擎变成另一种语言。要让易翻译准确识别吉尔吉斯文,关键在两件事:让应用能“看到”清晰的文本(高质量图片、合适裁切、正确方向),以及让应用知道“这是吉尔吉斯语”——也就是把源语言设对或下载相应的语言包(如果有离线模式)。理解这两点,后面的操作就是把步骤一步步落实。
为什么要特别注意吉尔吉斯文?
吉尔吉斯语现在主要用西里尔字母书写(跟俄文类似),但历史上还有拉丁或阿拉伯字母的变体,印刷体、手写体、道路标志或混合俄语的场景都会影响识别。OCR最擅长的是清晰、规范的印刷文本,对于手写、磨损或低对比度的照片准确率会下降。因此,在设置与拍照时就要针对这些特点优化。
常见影响识别的因素(别忽视这些)
- 字母系统:现代吉尔吉斯多为西里尔字母,确认源语言;历史或特定场景可能用拉丁/阿拉伯。
- 混合语言:吉尔吉斯语文本里常夹杂俄语或英语,可能需要手动选择“多语言”或切换检测模式。
- 图片质量:模糊、比例失真、反光、阴影都会影响OCR。
- 字体与排版:非常规字体或连写手写会降低准确率。
一步步实操指南(带细节的操作步骤)
下面按从打开应用到获得最终翻译的顺序写,尽量把每个按钮/位置说清楚(不同版本的文字可能略有差异,但逻辑是一样的)。
准备工作(必做)
- 确认手机已安装最新版本的易翻译,旧版本的识别或语言包可能不全。
- 授予应用必要权限:相机、存储(或相册)、麦克风(若有语音功能)。没有权限会导致拍照或导入失败。
- 检查网络:如果你打算使用在线识别/翻译,需要连网。若经常离线使用,建议下载吉尔吉斯离线包(见下)。
在易翻译里设置拍照识别吉尔吉斯文(逐步)
- 打开易翻译,进入主界面,找到并点击“拍照取词”或“拍照翻译”功能(通常以相机图标或“拍照”字样显示)。
- 第一次使用会弹出权限请求,允许相机和存储访问;如果之前拒绝过,去系统设置里手动打开权限。
- 在界面顶部或侧边找到语言选择栏:将左侧(源语言)设为“吉尔吉斯语(Kyrgyz)”。如果看不到,点击“更多语言”或“搜索语言”输入“吉尔吉斯”或“Kyrgyz”。
- 右侧选择目标语言(例如中文、英文等)。如果要让应用自动判断源语言,可以先尝试“自动检测”,但对于吉尔吉斯—尤其是夹杂俄语的文本,手动指定可能更稳定。
- 如果应用提供“离线包下载”或“语言包管理”,建议下载吉尔吉斯离线包(占用一定存储),离线包能在没有网络时提高成功率并保护隐私。
- 选择“拍照”或“导入图片”:对准文本拍摄或从相册选择已拍图片。拍摄时注意对焦和光线(下面有细节提示)。
- 拍完后,通常会出现可拖拽的识别框,调整框选范围只覆盖目标文本,避免干扰文字或背景。确认后点击“识别/翻译”。
- 等待OCR识别并显示文字,随后显示翻译结果。若识别结果有错,可手动编辑识别文字后再翻译,有时先修正比直接翻译更准确。
- 最后可选择复制、保存或分享翻译结果,或者导出识别文本(视易翻译的功能而定)。
表格:快速步骤一览
| 步骤 | 动作 |
| 1 | 打开易翻译 → 进入“拍照取词/拍照翻译” |
| 2 | 授予相机与存储权限;更新app |
| 3 | 设置源语言为“吉尔吉斯语”,目标语为中文或所需语言 |
| 4 | (可选)下载吉尔吉斯离线包 |
| 5 | 拍照或导入图片 → 调整识别框 → 点击识别/翻译 |
| 6 | 查看识别文本 → 必要时手动修正 → 查看最终翻译 |
常见问题与排查(有点像诊断表)
识别不到文字或显示乱码
- 检查是否把源语言设为吉尔吉斯语;有时默认是“自动”,会误判为俄文或其他语言。
- 确认图片是否清晰:试着重新拍一张更稳定且对焦好的照片。
- 如果是手写或老式印刷,OCR本身就难以完全识别,尝试放大、提高对比度或切换到“文档模式”。
翻译结果很离谱
- 先看OCR识别出的原文是否正确;多数错误来自识别错误而非翻译算法。
- 尝试切换在线/离线模式:在线通常更准确但会上传图片到服务器(见隐私);离线保密但可能词库有限。
- 对于专有名词、地名或缩写,手动校正OCR后再翻译通常更靠谱。
找不到吉尔吉斯语选项
- 应用语言列表可能按常用排序,把“更多语言”或“全部语言”展开再搜索“Kyrgyz”或“吉尔吉斯”。
- 若确实没有,检查是否为地区版本限制或较旧的app版本,尝试更新或联系官方支持。
提高识别成功率的实用技巧(原理+操作)
- 拍照技巧:靠近但不要太近以免模糊,保持手机与文字平行,避免强烈反光(比如光滑塑料或薄膜),最好有均匀光源。
- 裁切:用识别框只覆盖需要翻译的文字区域,避免太宽泛的背景干扰算法。
- 分段识别:长段落可以分多次拍照识别,这样OCR误差更小。
- 多语言并列:如果文本有俄语或英语,先用“多语言识别”或分别识别再手动合并翻译。
- 后处理:对专业术语或人名采用人工校对;可以把识别结果复制到笔记或字典进一步核对。
隐私与离线策略(你可能会关心)
简单来说:在线识别通常把图片或文字上传到服务器进行更强大的OCR+翻译,准确率高但要把数据传出去;离线识别在本地进行,更安全但依赖本地离线包的质量。根据场景选择:比如涉密文档尽量用离线包或把图片拍成局部截图并在本地处理。记得在设置里查看“隐私/数据处理”条款,确认应用的图片与日志处理策略。
如果你遇到特殊场景(门牌、手写、路牌)怎么办?
这些场景往往不规范:门牌和路牌字体粗大但可能有反光,手写则形态多变。如果是门牌/路牌,尝试:平拍、降低曝光、裁切背景;如果是手写,尽量拍多张从不同角度或手工抄写关键字再识别。对于拍照失败的场景,人工录入关键单词然后用文本翻译往往更快。
小结前的几个实战小贴士(说完就走,嗯)
- 先把源语言固定为吉尔吉斯语,避免自动检测误判。
- 拍照要稳、要清、要平行,裁切只保留文字部分。
- 下载离线包能在没网或担心隐私时更安心。
- 遇到低质量识别,先纠正OCR再翻译。
- 如果长期需要高准确度,考虑把识别结果导出给人工校对(或者结合专业术语词典)。
好了,操作上就是这些步骤——说白了,拍照识别吉尔吉斯文并不复杂,关键是把“语言设对”“照片拍好”“必要时下载离线包”这三点做好。实操时你可能会遇到小问题(像权限没开、找不到语言、识别框不准等),按照上面的检查清单逐项排查即可。假如你遇到特别怪的情况,告诉我具体场景和截屏(如果能描述文字样式和光线),我可以再靠细节帮你定位。就到这里,先去试试看吧——有时候多拍两张,准确率就上来了。