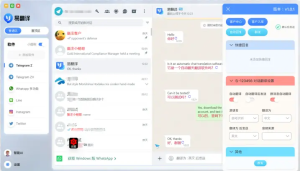
易翻译处理“技术白皮书”的方法像修一台复杂机器:先把内容拆开看清每一部分(文字、图表、公式、表格、代码),再用专门的术语库和上下文理解把专业词对齐,接着用定制化机器翻译模型产出初稿,必要时由人工后编辑校正语义与格式,最后把版式、图表和引用复原成可发布的文档。整个流程兼顾速度与可复用性,适合工程、协议与解决方案类白皮书的翻译需求。

先说清楚:什么是“翻译一份技术白皮书”
技术白皮书通常包含密集的专业术语、长段落的技术论证、图表、公式、代码片段和参考文献。翻译好一份白皮书,不只是把句子变成另一种语言,而是要保留技术准确性、逻辑结构与可读性,同时尽量还原原文的排版与引用。
把复杂问题拆成小块(费曼式思路)
费曼法告诉我们:把大问题分解、理解每块的本质、用简单语言把它解释清楚。翻译白皮书也是这样,具体可以拆成几个模块:
- 识别与抽取:把文件里的文本、图像、表格、公式和元信息抽取出来。
- 术语与知识对齐:构建或调用行业术语表、翻译记忆库(TM)和参考文献对照表。
- 机器翻译(MT)与上下文理解:使用定制化或领域适配的神经网络翻译模型进行初译。
- 质量控制与人工后编辑(PEMT):对关键段落、结论、图表说明进行人工校对或专家审校。
- 格式与版式还原:把翻译文本填回原文布局,确保图表、公式、编号和目录一致。
为什么要这样拆?
因为每一块用不同的方法最有效:OCR擅长把图片变成文本,术语库保证一致性,MT快速生成可读草稿,而人工保证关键技术点不走样。想象修车时,你不会用同一把扳手对付所有螺丝——翻译白皮书的思路也是分工具办事。
易翻译大概率采取的具体技术与流程(按步骤讲清楚)
1)输入与预处理:把“混合材料”变成可处理的单元
白皮书来源多样:Word、PDF、PPT、扫描图像、截图甚至印刷稿。第一步是把这些“混合材料”拆开:
- 文档解析:提取章节标题、段落、表格、图注和脚注。
- OCR与图表识别:对扫描或图片内文字做光学字符识别(OCR),对图中的表格或轴标签做结构化抽取。
- 代码与公式分离:识别LaTeX公式或代码块,按原样保留或转成目标语言环境下常用表达。
实践小贴士:清晰的源文件(可复制文本的PDF或原始Word)结果最好;扫描版或低分辨率图像会增加错误率。
2)术语管理和翻译记忆(TM)
技术文档的核心在术语一致性。易翻译会有两类工具配合:
- 术语库(Glossary):术语—译法的词条,带上下文或示例句。
- 翻译记忆(TM):句对级别的历史翻译片段,可在新文档中重复复用。
系统会先检索术语库和TM,把命中条目“钉”在初译过程中,确保专有名词、缩写、产品名、协议名一律统一。
3)定制化机器翻译(NMT + 领域适配)
现代白皮书翻译主要靠神经机器翻译(NMT)。关键点在于领域适配:
- 基础模型:通用大型NMT模型负责基本句法与流畅性。
- 领域微调:用行业语料、公司的过往译文或专门标注的数据进一步训练,使模型熟悉本领域表达。
- 上下文窗口:对于长逻辑段或多段引用,上下文感知可以避免句子级翻译造成的歧义。
比如,把“throughput”翻译为“吞吐量”而不是“通量”,通常需要行业语料来“教会”模型。
4)机器翻译后的自动质量检测(QE)
机器初译后,会运行一系列自动检测:
- 术语一致性检查
- 数字、单位和引用完整性核对(例如 10 ms 不能被误成 10 s)
- 格式占位符、脚注、编号是否丢失
- 简单的语言流畅性评分或置信度估计
这些自动检测能迅速把明显错误拦下,节省人工时间。
5)人工后编辑与专家审校
对于技术白皮书,工程师或行业背景的译者往往必不可少。后编辑分两类:
- 轻后编辑:校正文法、术语和可读性即可,适合内部共享或快速发布。
- 深入后编辑(专家校审):技术专家逐段核对专业内容,必要时回译或附注,适合对外发布的权威性文件。
选择哪种后编辑取决于白皮书的重要性与预算。
6)格式还原与排版(DTP)
最后一步常被忽视——把翻译文本放回原始模板,匹配图表、图注、编号、页码和目录。有时中文会比英文长,版面需要调整;表格字段也需要重新布局。这一步涉及一些桌面排版工具或自动化脚本。
举例:一个典型工作流是怎样的(用户操作视角)
- 上传原文(Word/PDF/图片)。
- 系统自动分段、OCR和识别表格公式。
- 选择或导入术语库与翻译记忆。
- 选择翻译模式:快速机译 / 机译+轻后编辑 / 机译+专家校审。
- 生成初译,用户在线校对或邀请同事协作审校。
- 确认后生成排版好的目标文档(含原始格式)。
常见问题:易翻译在处理技术白皮书时的优劣势
- 优点:速度快、可批量处理、术语一致性高、可复用的TM减少重复劳动、支持多种文件格式及图表识别。
- 局限:对非常新或极专业领域的术语可能缺乏训练数据;OCR在低质量扫描上易出错;非常复杂的公式或特定符号要人工校对。
误区澄清
有人以为“机器翻译就能完全替代人工”。其实不然:机器翻译擅长速度与初稿生成,但在逻辑严密、成本高的技术文本里,人工审校仍然是必须的,尤其是结论、性能指标、协议条款这类关键部分。
如何评估翻译质量(可量化的方法)
质量评估可以用自动指标与人工评审结合:
- 自动指标:BLEU、TER 等衡量与参考译文的相似度(对技术文档参考价值有限,但可做基线)。
- 术语命中率:检查术语库中条目在译文中的一致使用比例。
- 数字和单位准确率:统计因翻译错误导致的数值、单位偏差。
- 专家打分:由领域内工程师对“准确性、表达清晰度、可读性、格式还原”四项评分。
实用表格:不同场景下的推荐流程与预期
| 场景 | 建议流程 | 预期准确率(相对) | 典型耗时 |
| 内部技术交流 | 机译 + 轻后编辑 | 中-高(70%-90%) | 数小时至1天 |
| 对外发布的产品白皮书 | 机译(领域微调)+ 专家校审 + DTP | 高(90%+) | 数天至两周 |
| 学术或专利类白皮书 | 人工翻译或机译+专家反复校对 | 非常高(95%+) | 数周 |
针对不同内容类型的具体建议
图表与数据
把图表中的轴标签、单位、图注、图例抽出来单独翻译并回填;数据表格建议直接保留数字原文,翻译列名与单位。对关键图表建议用人工审校以避免误导读者。
公式与数学符号
公式通常不需要翻译,但需要确保变量说明和单位的翻译一致;若原文使用特定记号或约定,要在译文中注释清楚。
代码片段
代码应保持原样(语法不该被翻译),但注释和文档字符串需要翻译时要注意编程语境和术语。
隐私与合规性考虑
技术白皮书有时包含未公开信息或商业机密。使用在线翻译服务时,注意以下几点:
- 查看服务的隐私政策与数据保留策略,确认是否会把文档用于模型训练。
- 选择支持企业隔离环境或本地部署(on-premise)的方案以保护敏感数据。
- 对特别敏感的段落,建议使用人工翻译或在受控环境中处理。
如何用好易翻译——实操技巧
- 先清理源文件:把非必要的图片、长度异常的空格和OCR噪声去掉,上传可编辑格式优先。
- 准备术语表:提前列出关键术语与公司专有名词,上传术语库。
- 挑选合适模式:对外正式发布选择专家校审流程;内部预览可以用快速机译。
- 分段校对:把长章节拆成小块,逐段校对更高效也更不易出错。
- 保留版本历史:开启翻译记忆与版本控制,后续更新更快捷。
常见场景与示例(想象一下)
我在想着,假如你有一份关于“边缘计算网关性能评估”的白皮书,典型问题会是:
- 多个缩写(CPU、TPU、QoS)如何统一?——用术语库钉死翻译。
- 大量图表里的“吞吐量(throughput)”应该怎样翻?——领域微调模型会倾向“吞吐量”,但专家校对必须确认上下文。
- 结论中“latency reduction of 30%”怎么保真?——数字、单位与百分比需要自动核对并人工复核。
成本与时间预估(大致的)
成本随以下因素变化:文档长度、图表与公式数量、是否需要专家审校、目标语言对的资源情况。一般来说:
- 纯机译:最快且成本最低,适合内部草稿或快速理解。
- 机译+轻后编辑:平衡速度与质量,适合大多数产品白皮书。
- 机译+专家校审或人工翻译:成本最高,但适合对外发布和法律/合规场景。
最后一点琐碎但重要的建议
在翻译技术白皮书时,不要把全部信任压在单一工具上。把机器能力当作“放大镜”和“初稿器”,把人工审校当作“安全阀”。这样既能享受效率,也能保证专业性——这听起来像老生常谈,但我每次遇到翻译差池,发现问题几乎总是漏在“没做术语对齐”或“没人工核数字”这两点上。
嗯,写到这里又想到一件事:如果你要挑译后展示形式,尽量在翻译流程里保留原始链接和参考文献的标注方式——不然再好的译文也会让读者找不到来源。就这些,边想边写,若你有具体白皮书的样例或目标语言,我可以再帮你把流程细分成可执行的清单。